
Por Ana Carolina Aires, João Victor Escovar e Matheus Lopes Cardoso
A cada dia que passa, a tecnologia surpreende com novas funcionalidades, por meio da facilidade de conexão criada pela internet, quase que onipresente na vida dos indivíduos. Telefones celulares cada vez mais modernos e aplicativos de uma praticidade fantástica nos oferecem serviços para auxiliar o dia-a-dia. Contudo, as maravilhas apresentadas possuem uma contrapartida: o fornecimento de dados. Sempre que visitamos um local conectados à internet ou GPS, preenchemos formulários online, efetuamos transações bancárias ou interagimos nas redes sociais, deixamos rastros de nossa privacidade e de nossas preferências aos fornecedores dos valiosos serviços.
O fato de que tudo que fazemos conectados ficar registrado provocou o surgimento de um amplo conceito na área de Tecnologia da Informação: o Big Data. Traduzido ao pé da letra como “grandes dados”, o termo, na realidade, se refere a um conjunto de informações muito amplo que, exatamente por isso, carece de meios para lidar com seu tamanho, de maneira que qualquer dado possa ser interpretado e analisado em tempo hábil.
A tendência é que a importância da questão de como captar e utilizar os dados gerados só aumente com a evolução tecnológica. Daqui a algumas décadas, a internet deve estar presente não somente nos celulares e computadores, mas em equipamentos como geladeiras, carros ou máquinas de lavar roupa. Os dados gerados vêm aumentando exponencialmente a cada ano e este padrão deve ser mantido. De acordo com expectativas da empresa IBM, por exemplo, 90% dos dados armazenados atualmente foram produzidos apenas nos dois últimos anos.
As aplicações de um manejo eficiente de dados podem beneficiar e otimizar diversos setores da sociedade, como o poder público, no que concerne à organização de toda a estrutura e fiscalização estatal; os bancos, que podem facilitar transações e aumentar a segurança de investimentos; os sistemas educacional e de saúde, pela análise de suas deficiências e das necessidades dos usuários; além de empresas, que podem compreender melhor as preferências de possíveis clientes e projetar planos de ação personalizados. Contudo, a possibilidade que melhor vem sendo explorada é a de vender informações para companhias ou condicionar conteúdos e publicidade para cada indivíduo, como tem demonstrado o exemplo das gigantes da informática, como Google e Facebook – cujos serviços estão presentes no cotidiano da população de maneira incessante.

Para o sucesso da análise do Big Data, é necessário observar, no mínimo, três aspectos dos dados: seu volume, sua velocidade e sua veracidade. O volume refere-se à grande quantidade disponível de informações, que restringe a utilização pela dificuldade de análise; a velocidade se deve à rapidez com que tudo flui no mundo digital, que é bem maior do que aquela que acompanhamos enquanto humanos; a veracidade, por sua vez, comporta a necessidade de que os dados sejam reais e confiáveis para que sua aplicação seja útil e consistente.
A máquina e o homem
Se cada email enviado ou cada comentário em redes sociais é registrado, o volume de dados criado por dia é assustador. Quando se fala em Big Data, entretanto, não se trata de um único grande armazém em que toda a informação fica retida: cada site, software ou empresa possui suas informações.
“Os dados estão distribuídos de maneira muito diversa”, explica o professor do Departamento de Ciência da Computação do Instituto de Matemática e Estatística da Universidade de São Paulo (IME-USP), Marcelo Finger. “Existem os dados estruturados, que são aqueles salvos em bancos de dados, sobre os quais é possível impor respostas desejadas, como as informações de funcionários de uma empresa guardadas em um planilha, e os não-estruturados, ou seja, soltos pela internet, em matérias escritas, sites diversos ou redes sociais”.
Segundo Finger, ainda existem muitos entraves para uma aplicação perfeita do potencial dos dados, que fogem à própria compreensão dos pesquisadores da área. “Com o advento da internet, houve uma explosão da produção de dados como nunca e o Big Data são as técnicas que vêm sendo desenvolvidas a fim de aproveitar todo esse material”. Entretanto, embora muito se fale do tema, o professor considera que ele ainda está longe de ser estabelecido. “Não entendemos muito sobre a imensidão de informações e estamos tentando fazer isso aos poucos”.
O processo de interpretação dos dados consiste em trazê-los para um computador ou software já programado, indexá-los e obter respostas. O grande problema é que os dados dificilmente estão disponíveis e estruturados, de maneira a facilitar o trabalho da máquina. O tratamento não é, desse modo, algo compreensível em termos da inteligência humana, como se os programas de computador e seus desenvolvedores fossem assustadoramente dominantes de um conhecimento fantástico: os resultados vêm de ações pré-programadas.
Mesmo assim, o tema ainda assusta a população. Para o professor, isso é fruto do medo natural que temos do novo e do desconhecido. “O surgimento de novas tecnologias sempre foi motivo de grande ansiedade para o ser humano. Isso é justificável, pois existe um sentimento de prevenção a possíveis males: quando não compreendemos plenamente o funcionamento de algo, temos medo. A história do Frankenstein é um claro exemplo disso, numa época em que a medicina florescia”, explica.
Embora seja natural e talvez até exagerado o receio humano, a população deve interagir no que rege o mundo virtual e a geração de informações. “Temos de criar modos de conviver com a tecnologia, regulando seu funcionamento, seja para uso cotidiano, seja para usos específicos, como o militar. O Big Data não atinge apenas as máquinas e os programadores, mas toda a sociedade. Desse modo, é a sociedade quem deve participar da implementação das novas tecnologias. Os especialistas não podem ser os únicos a opinar. Pelo contrário: a população deve discutir o que pode ser feito, além de conhecer como se proteger e verificar os dados fornecidos”, argumenta Finger.
Outros pontos que o pesquisador acredita ser de relevância social estão ligados aos direitos de cada parte envolvida na geração de dados. “Hoje, milhões de usuários fornecem dados a empresas de internet, como Google e Facebook, que ganham muito dinheiro com tudo isso, e não questionam a propriedade desse uso. Quando surgem novas tecnologias, muitas vezes elas estão baseadas num precedente anterior, que nem sempre é o melhor para sua aplicação e precisa ser melhorado”.
Cidades Inteligentes
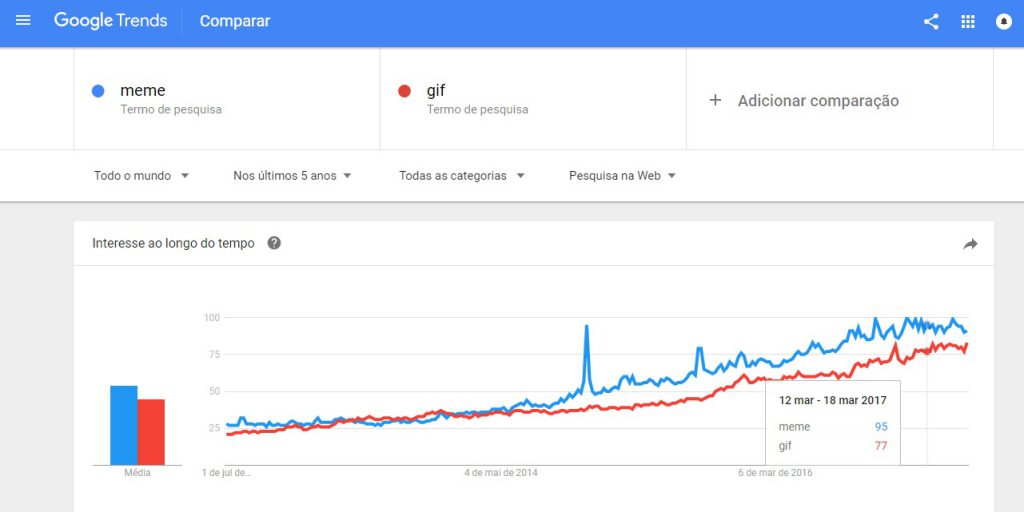
As aplicações do Big Data originalmente estão ligadas às grandes corporações que, inicialmente, eram as únicas capazes de coletar, organizar e selecionar uma grande quantidade de dados, transformando-os em informações relevantes, capazes de potencializar o negócio. Com a chegada do Google, em 1998, passa a ser possível realizar uma mineração de dados com ferramentas simples e intuitivas, especialmente a partir de 2005, com o surgimento do Google Analytics – ferramenta capaz de coletar e sintetizar informações de um site, gerando, por exemplo, relatórios de visitas diárias, tipos de tráfego e tempo no site por país – e o Google Trends – ferramenta que aponta a frequência de termos procurados e que foi, posteriormente, adotada por outros sites, como o Twitter e o Youtube.
O crescimento das possibilidades de uso de dados fez com que a comunidade científica se voltasse a estudá-los, buscando aprimorar suas aplicações e criar novas formas criativas e de uso. Fabio Kon, professor da área de ciência da computação, também do IME-USP, debruçou-se sobre pesquisas de coleta e aplicação de dados no cotidiano, a fim de aprimorar a gestão das cidades e tornar o dia-a-dia mais prático. Focado no estudo de Cidades Inteligentes – que utilizam recursos tecnológicos, como Internet das Coisas, Big Data, computação móvel e em nuvem, para processar informações no meio urbano –, Kon acredita que o emprego de dados nesse contexto precisa caminhar em conjunto com o desenvolvimento de softwares livres.
Software livre é aquele que qualquer um pode ter acesso ao código fonte, ou seja, a todas as instruções em linguagem de programação existentes em sua construção, possibilitando a execução, cópia, modificação e aprimoramento deste código e, consequentemente, do programa em si. “Com isso, podemos ter a certeza de que estamos sempre aprimorando nossas ferramentas de análise e uso de dados, caminhando para frente e não reproduzindo o que já foi feito antes”, pontua. Juntamente com o desenvolvimento de softwares livres, Kon aponta a necessidade de aumento das conexões Wi-Fi pela cidade, facilitando o fluxo e a agilidade de informações coletadas, bem como a liberação de acesso aos dados coletados nos diversos âmbitos da cidade, que, muitas vezes, são retidos pelos poderes públicos.
Joyce Bevilacqua, pesquisadora na área de epidemiologia matemática e também professora do IME, trabalha com dados de saúde pública – em especial relacionados à dengue – e atesta que os órgãos governamentais possuem uma quantidade imensa de dados crus que são retidos. “Quando eles divulgam, já fizeram uma curadoria que não necessariamente foi dentro do escopo que todas as áreas de pesquisa precisam”, afirma. A professora pontua que, como os dados brutos não são públicos, é necessário realizar processos burocráticos para consegui-los e, às vezes, quando chegam, já podem estar desatualizados e não serem mais eficientes para a pesquisa.
A aplicação do Big Data no aprimoramento da gestão das cidades já é realidade em várias cidades do mundo, inclusive São Paulo. A liberação de acesso aos dados de GPS dos ônibus possibilitou, por exemplo, que a startups Scipopulis, formada por ex-alunos da USP que trabalharam em conjunto com Kon, desenvolvesse uma plataforma de oferecimento de serviços de mobilidade urbana. Por meio do aplicativo, a startup permite que os cidadãos acompanhem o tempo de espera dos ônibus e oferece, ainda, suporte à SPTrans e à CET, por meio do Painel do Ônibus, uma estrutura web que fornece informações em tempo real e históricos que auxiliam a gestão, o planejamento e a operação do sistema de transporte coletivo, indicando, por exemplo, a velocidade média em corredores exclusivos e faixas de ônibus.
Informação e comunicação
O grande fluxo de dados é algo que traz benefícios, como facilidades no cotidiano e no acesso à informação, e malefícios, entre eles o receio em relação à tecnologia e à perda da privacidade. Além disso, pode ser usado como fonte de renda, potencializando negócios já existentes ou atuando como um produto em si.
Para a pesquisadora na área de comunicação, negócios e mídias digitais da Escola de Comunicações e Artes da USP, Stefanie Silveira, os serviços que nos são oferecidos, aparentemente de graça, têm um preço. “Não é raro ver pessoas que utilizam o Facebook ou os serviços do Google surpreendendo-se pela gratuidade deles. Não pagamos com dinheiro, mas oferecemos nossos dados, dos quais eles tiram dinheiro”, afirma. “Existe uma facilidade de organização como nunca houve. Contudo, para usufruí-la, temos de abrir não de nossa privacidade. Os celulares são sensores que andam conosco. Não há privacidade estando conectado”.
Em relação à comunicação, os softwares e algoritmos utilizados pelos provedores de conteúdo, como o Facebook, têm isolado cada vez mais as pessoas em suas ideias e contextos culturais, a despeito da aparência de uma conexão de diversas realidades. “Estima-se que o algoritmo do Facebook, por exemplo, possua mais de 100 mil regras para determinar o que vemos em nosso ‘feed’ de notícias. Ele se distingue dos algoritmos comuns de programação, pois é capaz de aprender, trabalhar com uma quantidade infinita de dados e se adaptar a cada nova página ou perfil criado. É algo que se assemelha à inteligência artificial”, explica Stefanie.

Conforme conta a pesquisadora, a percepção desses algoritmos é capaz de detectar sentimentos e significados nas interações digitais: eles são conduzidos pela nossa linguagem, percebem nossa cultura, trabalham com dados não-estruturados e se modificam a cada dia.
Com essa percepção é possível regular, como faz o Facebook, as publicações e conteúdos que vemos, o que pode nos inserir numa “bolha” ideológica e cultural. “Baseado em nossos interesses, o Facebook traça um perfil individual e nos mostra aquilo que desejamos ver. Em média apenas 20% do que teríamos acesso nos é mostrado. Isso provoca uma dificuldade de entendimento da diversidade e do mundo real: tudo o que vemos está alinhado à nossa própria visão”, alerta.
Questionada sobre a consciência que temos do que fornecemos e sobre os perigos que a sociedade pode correr, Stefanie é categórica: “As pessoas não sabem o quanto são conhecidas. O Big Data já influencia o processo democrático e a manipulação das mídias. Pensamos que a internet é o grande expoente da democracia, mas isso não é verdade, pois o sistema vigente sempre encontra meios escusos. Existem empresas especializadas em gerar boatos e notícias falsas, por exemplo”.
Sobre o medo de possíveis ameaças cibernéticas, já retratado diversas vezes pelo cinema, a pesquisadora afirma que ainda estamos distantes desse ponto, mas que pensá-lo não é nenhum absurdo, se interpretarmos a influência da informática na própria organização da sociedade atual. “Muitos dos inventos foram criados com uma intenção e utilizados com outra, como a bomba atômica. É um campo novo e em exploração, não sabemos até onde se pode chegar”.
Impacto nos negócios
A análise do grande volume de dados disponível exige o uso de softwares e planilhas especializados, além da figura do cientista de dados, um especialista em programação computacional, estatística e matemática. Para Stefanie, caso as empresas atentem-se para essas questões, elas poderão desfrutar do que chama de “novo petróleo”. “Além do uso feito por empresas como Facebook e Google, que consiste na venda de dados, as empresas podem investir na construção de perfis de consumidores, direcionando seus produtos, serviços, conteúdos e publicidade”, explica.
Para a estudiosa, um grande exemplo desse potencial não aproveitado é o das empresas jornalísticas, em especial as brasileiras. “Os setores de comunicação ainda não sabem como utilizar a disponibilidade de dados. Como sua função é disponibilizar conteúdo para cada indivíduo, agir no contexto de uma personalização do jornalismo seria uma inovação muito positiva para essas empresas, que hoje passam por uma crise. Além disso, elas possuem grandes bancos de dados, em virtude das fichas de seus assinantes e cadastrados, o que possibilita uma análise muito bem feita do público consumidor”, destaca.
Esta possibilidade, inclusive, é uma das que as empresas podem se valer para obter dados: fazendo a própria captação. Outra alternativa seria a compra de bancos de dados ou da armazenagem dos sites e serviços digitais.
Dados psicológicos irrastreáveis
Em 2008, Michal Kosinski, em um programa de doutorado no Psychometrics Center da Universidade de Cambridge, desenvolveu um sistema capaz de analisar a personalidade e as características psicológicas das pessoas por meio de análises dos seus dados, como curtidas em posts e páginas do Facebook. Tendo como parâmetro o método de medição de traços psicológicos conhecido como Big Five, que analisa cinco aspectos da personalidade – Abertura (a novas experiências), Consciencialidade (perfeccionismo), Extroversão (sociabilidade), Condescendência (cooperatividade) e Neuroticismo (temperamento) –, Kosinski conseguiu, por meio da interpretação de perfis nas redes sociais, determinar com exatidão a personalidade correspondente dos usuários no Big Five.
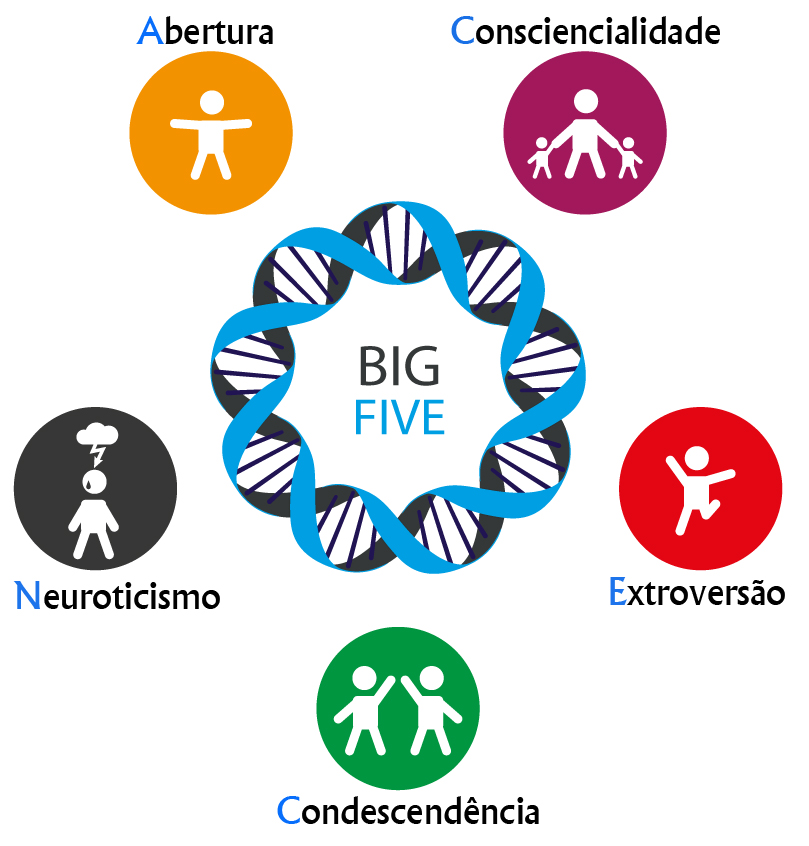
Tudo isso foi possível porque, anos antes, David Stillwell (colega e parceiro de projeto de Michal Kosinski) criou um aplicativo chamado MyPersonality que, como um jogo, fazia as pessoas conectadas ao Facebook responderem perguntas muito semelhantes às realizadas no teste psicológico Big Five. A partir dessa coleta de dados de Stillwell, Kosinski começou a fazer relações pertinentes, como, por exemplo, a associação de que pessoas que curtiam Lady Gaga eram mais propensas a serem extrovertidas. A combinação de muitos desses dados simples e até genéricos tornou possível gerar previsões extremamente precisas sobre a personalidade dos indivíduos, por meio das redes sociais.
Para Adriana Vilano Dinamarco, mestre em Psicologia Clínica pelo Instituto de Psicologia (IP) da USP, apesar da análise e do uso de dados ajudarem a traçar uma personalidade, a estruturar pesquisas acerca do comportamento e a compreender um público e a situação de meio em que uma pessoa está inserida, é impossível que os dados façam o papel que o ser humano ocupa na avaliação psicológica, na área da psicanálise, por exemplo. “Ainda não conseguimos mapear o inconsciente por meio de instrumentos. O inconsciente é único, individual e faz parte da trajetória emocional de cada um que, nem sempre, está ‘registrada’ naquilo que os dados podem capturar”, afirma.
A utilização do Big Data influencia, também, na forma com que as pessoas estão inseridas em suas realidades. Adriana remonta o uso de dados a uma noção que se tem do Big Brother, de que estamos sempre sendo observados e de que nossa vida está sendo orquestrada pelo outro. “Quanto mais o Big Data avança, mais temos a sensação de que tudo que fazemos está sendo visto e pode ser arrumado e personalizado para nós. O consumidor, ao entrar em uma loja online, por exemplo, tem a sensação de que a loja é feita para ele, justamente porque o Big Data acaba armazenando dados de preferências capazes de direcionar a pessoa a consumir mais”. Do outro lado da moeda, Adriana ressalta que os donos das empresas podem ter uma falsa impressão de que, com esses dados em mãos, conhecem completamente seus clientes, como se não existissem mais mistérios acerca da individualidade das pessoas.
“Precisamos pensar na manipulação que pode ser construída a partir desses dados na mão de pessoas mal intencionadas. No caso da política, por exemplo, ao realizar uma pesquisa de dados comportamentais, seria possível identificar o que o povo quer ouvir, como ele quer ouvir e onde ele quer ouvir. Isso criaria uma campanha política direcionada”, alerta. Para a pesquisadora, entretanto, o uso do Big Data não é de todo maléfico e possui grandes contribuições em outras áreas. “A manipulação já existe de inúmeras outras formas, portanto, o Big Data seria somente uma forma de potencializá-la. O uso de dados em diversas esferas, inclusive psicológicas, pode e deve ser considerado, desde que visando a aprimorar o fazer científico e cotidiano”.



Faça um comentário