

Por Filipe Moraes, Júlia Queiroz e Tainá Rodrigues
Em uma união entre o passado e o presente, pesquisadores do Instituto de Estudos Avançados (IEA) da USP utilizaram recursos tecnológicos, como a inteligência artificial, para estudo e aplicação na língua indígena. Por meio de trabalhos de campo com comunidades nativas, criação de protótipos e adaptação de mecanismos, especialistas da área da tecnologia têm trabalhado a possibilidade de inserção dessas ferramentas para preservar, revitalizar e traduzir línguas nativas do Brasil.
Segundo dados coletados pela IBM Research Brazil de 2024, a diversidade linguística global está diminuindo. Atualmente, existem cerca de 7 mil línguas faladas no mundo todo, e 43% delas estão sob ameaça de desaparecimento. Dessas línguas faladas pelo globo, 4 mil são faladas por povos indígenas, uma quantidade relevante e que explica o interesse de pesquisadores e linguistas por sua manutenção. Ainda assim, a pesquisa demonstra que 95% dessas línguas nativas correm risco de desaparecer nos próximos 100 anos.
Para o professor visitante do Instituto de Estudos Avançados (IEA), Claudio Pinhanez, uma das problemáticas envolvidas na questão das línguas indígenas e suas constantes ameaças de desaparecimento está no subconsciente da população em geral, que costuma dar pouca ou nenhuma importância ao assunto. “O que observamos, como pesquisadores, é que as pessoas costumam se importar mais com o desaparecimento de uma determinada espécie animal ou vegetal ou a destruição de um patrimônio histórico do que com o desaparecimento de uma língua nativa. E isso é um grande problema, já que a língua é parte essencial da cultura e da história, não só da comunidade mas de todo um país”.
No Brasil, o cenário de inserção de inteligências artificiais têm se debruçado sobre o tupi antigo, uma língua que é considerada “dormente”, ou seja, que já foi considerada morta e hoje passa por um processo de revitalização. Atualmente, alguns grupos indígenas dos estados do Espírito Santo, como os Tupiniquim, e da Paraíba e Rio Grande do Norte, como os potiguara, têm demonstrado interesse em adotar essa como sua nova língua, depois de perderem seu idioma nativa durante o processo de colonização.
O tupi antigo, que também era conhecido como língua brasílica na literatura do século 16 e 18, foi a mais falada em toda a costa brasileira durante o período colonial, adotada pelos jesuítas para facilitar a catequização dos indígenas estabelecida como a principal no tronco do tupi guarani. Porém, em meados do século 18, foi proibida em todo o território nacional devido às tensões entre a Coroa Portuguesa e a Companhia de Jesus, culminando na expulsão deste último do território e consequente perda de força da língua para além da região amazônica.
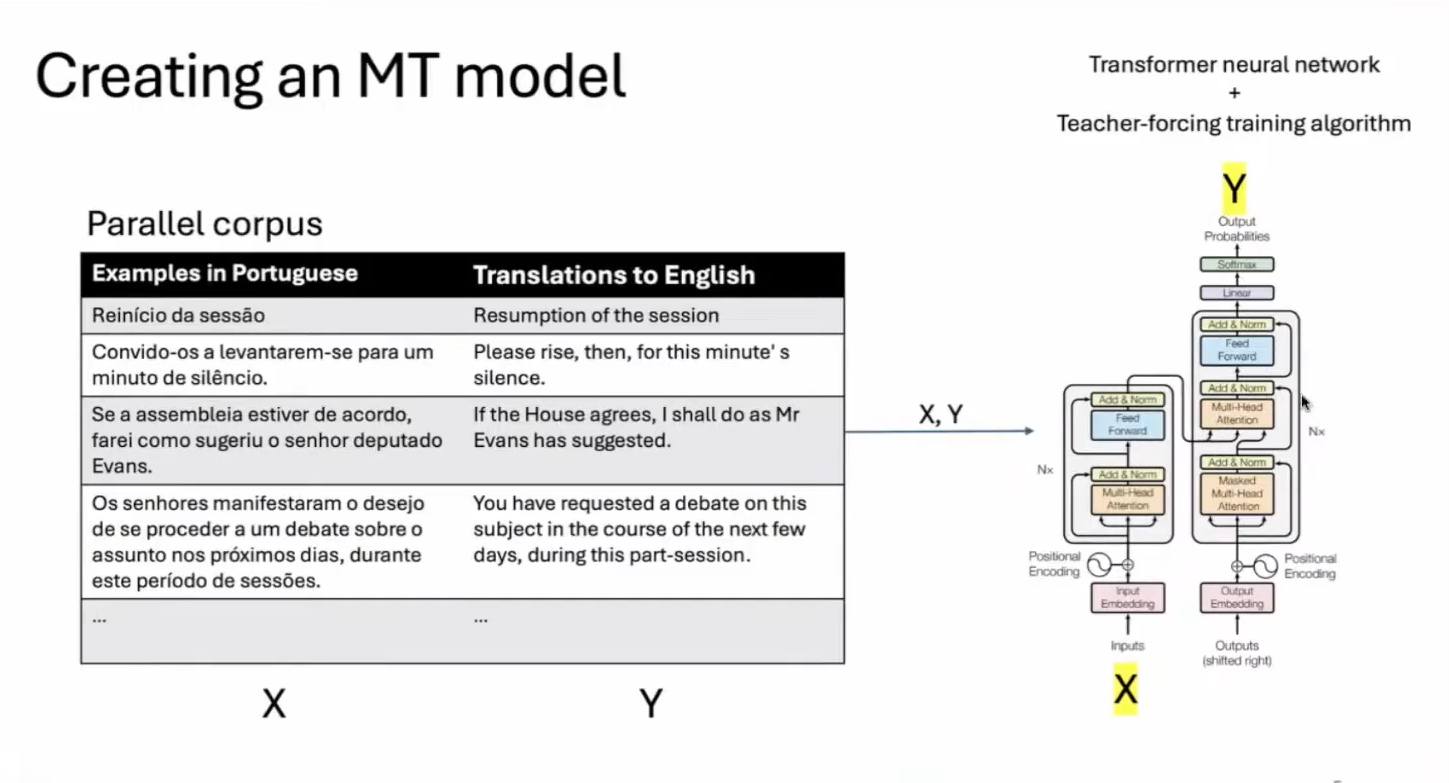
Baseando-se na importância e nos esforços de revitalização e preservação, pesquisadores do IEA estudam formas de desenvolver ferramentas, a partir da inteligência artificial, que funcionem como um tradutor para essas línguas indígenas. Segundo Paulo Cavalin, profissional da área de tecnologia envolvido no projeto do Instituto, em linhas gerais “o machine translation é o sistema essencial para esse processo, em que há um texto escrito em linguagem de máquina e que é traduzido para a língua desejada”. Ainda assim, o especialista destaca que existem outros modelos que podem ser adotados para a realização dessa tarefa, mas é “quase impossível obter uma forma fixa que possa ser usada para todas as línguas, principalmente as nativas no geral, já que cada uma possui suas especificidades”.
Um dos modelos que Cavalin destaca como mais utilizado no treinamento dessas inteligências artificiais é o Corpus Paralelo: uma divisão em duas colunas, em que de um lado posicionam-se textos na língua de origem e do outro estão as traduções equivalentes na língua de destino. A dificuldade está na alimentação desse tipo de modelo, que demanda muitos dados para seu treinamento e bom funcionamento, uma característica pouco observada nas línguas indígenas, que apesar de serem amplamente faladas em partes do território brasileiro, ainda possuem poucos dados digitalizados.
Esse tipo de tradução do tupi antigo através do uso de inteligência artificial enfrenta o desafio de que, por ser uma língua pouco falada nos dias atuais, a maior parte de seus registros foi feita nos séculos passados durante a colonização e a maior parte dos textos não foi digitalizada, como os de Padre Anchieta no século 16. Outra questão é que, ainda que existam alguns textos que possam ser resgatados e digitalizados para o uso, eles foram escritos por pessoas que aprenderam a língua mas não eram nativas e não foram alfabetizadas a partir dela, o que causa uma perda relevante de recursos e detalhamentos.
Professor do Departamento de Ciência da Computação da University of Exeter, Aline Villavicencio, aponta os desafios no processamento de línguas indígenas, começando pela escassez de recursos. “Trabalhar com línguas indígenas com menos recursos em comparação ao inglês é muito desafiador, principalmente pela menor disponibilidade de corpora [conjuntos de textos usados para pesquisas linguísticas], dicionários e outros insumos – quando eles existem”.
Além da falta de recursos, Villavicencio destaca a complexidade estrutural de muitas dessas línguas, que são polissintéticas. “As palavras são compostas por vários morfemas [as menores unidades de significado que compõem as palavras], e o que é aprendido para um não necessariamente se generaliza para os outros”. Essa característica exige que os modelos de linguagem sejam adaptados e ajustados para lidar com combinações variadas.
Segundo dados do Censo Demográfico realizado pelo Instituto Brasileiro de Geografia e Estatística (IBGE) em 2010, o Brasil registrou a existência de 274 línguas indígenas no país, onde vivem 817.956 mil indígenas de 305 etnias. A maioria dessas línguas possuem tradições orais em suas culturas, o que dificulta o seu registro e processamento. “Muitas dessas línguas possuem tradições orais, e, quando transcritas, apresentam variações ortográficas significativas”, aponta Villavicencio.
Além desses desafios, trabalhar com o processamento de linguagem natural em línguas novas implica testar continuamente como os modelos se comportam em tarefas específicas. O pesquisador destaca, por exemplo, as dificuldades que os modelos atuais enfrentam ao interpretar a linguagem figurada ou idiomática. “Os modelos não conseguem fazer o que um falante nativo faz rapidamente, que é reconhecer que certas palavras não devem ser interpretadas literalmente, mas sim de forma figurada.”
A partir de 2021, a Motorola incluiu nos teclados dos smartphones duas línguas indígenas da América do Sul: o Nheengatu e Kaingang. O projeto teve uma expansão para outras regiões do mundo — abarcando atualmente mais cinco línguas indígenas (Cherokee, Kangri, Kuvi, Maori e Ladin). Os povos falantes desses dois idiomas iniciais são nativos do Brasil, originários da região Sul e Norte, respectivamente.
A empresa de telecomunicações seguiu alguns critérios para escolher quais línguas seriam incluídas no teclado dos celulares smartphones. Segundo a especialista em Sistema de Informação e participante da pesquisa, Natália Falcão, a Unesco classifica o risco de extinção de alguns idiomas em categorias. “O primeiro passo era analisar quais línguas estavam em categorias de risco extremo ou considerável de extinção. O segundo passo é ir atrás da aceitação da comunidade e entrar em contato com professores.”
Falcão ainda revela que o projeto se iniciou com a língua Nheengatu, em que um engenheiro da Motorola entrou em contato com o professor linguista Wilmar D’Angelis, da Unicamp e, a partir disso, foram feitas pesquisas para dar seguimento ao projeto.

“O Unicode é o padrão de tecnologia da informação para codificar, representar e gerenciar o texto em um determinado sistema de escrita, no qual todos os padrões devem estar de acordo com cada idioma.”
Segundo a analista, o Unicode recebe suporte do ICU (Componentes Internacionais para Unicode), que é uma biblioteca de software de código aberto, utilizado na linguagem de programação. O ICU, por sua vez, compila os dados contidos em bibliotecas do CLDR (Repositório de dados de localidade comum).
“O CLDR é um lugar onde tem todas as informações dos idiomas, como por exemplo, código do idioma, formato de data e hora, fuso horário, unidades de medidas, plural e calendário [mês e dias das semanas]”, explica Falcão.
As linguagens e os usos das letras são diferentes e por isso, certas adaptações foram incluídas no teclado. “No português do Brasil, não utilizamos o y com acento e no Kaingang eles utilizam. Então, fizemos esse mapeamento com informações que os linguistas trouxeram pra gente e nós montamos o layout do teclado de acordo com a definição [dos indígenas]”.
Para conseguir integrar as linguagens no sistema Android, professores, linguistas e indígenas foram consultados. A empresa reitera que os povos nativos tinham que fazer parte do processo de inclusão digital, respeitando a cultura e colocando a comunidade como protagonista da pesquisa e da implementação da ferramenta.“O trabalho é sempre com a comunidade. Não adianta fazer algo achando que está certo.Essa comunicação é fundamental, assim como entender que cada cultura é diferente”, expõe a analista.
Posteriormente, os povos originários relataram como o acesso digital da língua contribuiu com o seu cotidiano. “Minha colega de trabalho conversou com uma pessoa da comunidade, que revelou ter conseguido digitar o TCC por ter um teclado disponível no idioma dela”, relembra Falcão. “Esse processo de tradução do idioma ajuda a fortalecer a língua. Então é muito importante ter esse contato com o pesquisador e com o linguista. Tudo isso ajuda a fortalecer a língua que pode estar em um determinado risco de extinção.”



Faça um comentário